- Business & Data Research
- Posts
- K-Means Clustering - Turkish eCommerce Products
K-Means Clustering - Turkish eCommerce Products
Mahesh Gurumoorthi
September 01, 2025
What is Clustering :
Each clustering algorithm comes in two variants: a class that implements the fit method to learn the clusters on train data, and a function that, given train data, returns an array of integer labels corresponding to the different clusters
Steps in the K-means algorithm
Input: Number of clusters to be formed as per the business case
Step 1: Assume K centroids (for k clusters)
Step 2: Compute the Euclidean distance of each object with these centroids
Step 3: Assign the objects to clusters with the shortest distance
Step 4: Compute the new centroid(mean) of each cluster based on each object’s clusters assigned
Step 5: Repeat steps 4 till we get convergence
Step 1: Import the required libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.spatial.distance import cdistTo show the plots in line use the below 😀
%matplotlib inlineStep 2 : The Dataset is currently in a txt file, hence we use functions to streamline the text files and create a dictionary
with open('/Users/Sample Datasets Kaggle/Clustering_Ecommerce/Turkish_Ecommerce_Products_by_Gozukara_and_Ozel_2016/All_Products/Raw_Entire_Dataset.txt','r') as file :
for line in file:
print(line.strip())
----------------------------
116;SAMSUNG G850 GALAXY ALPHA BEYAZ AKILLI TELEFON
462;HP Pavilion 11-n000nt Pentium N3540 4GB 750GB 11.6" Dokunmatik Win8 - K0W08EA
1286;Apple iPhone 6 Plus 16GB Cep Telefonu
1290;Samsung G850F Galaxy Alpha Cep Telefonu
1300;Samsung UE-48H6270 LED Televizyon
1665;Philips 18,5inç 193V5LSB2/62 5ms Led Monitör
2021;Sony Xperia M2 Dual ( Sony Türkiye Garantili )
2485;18,5 193v5lsb2-62 Led Monitör 5ms Siyah
2495;Stdr1000201 2,5" 1tb Bp Usb 3.0 Gümüş
2503;Dsc-w800 20.1mp 5x Optik 2.7" Lcd Dijital Kompakt Siyah
2580;Tefal GV8930 Pro Express Buhar Jeneratörlü Ütü
2838;Sony Xperia Z2 Cep Telefonu
2842;Samsung G850 Fiyatı
4376;Samsung Galaxy Alpstructured_data = {}
with open('/Users/Sample Datasets Kaggle/Clustering_Ecommerce/Turkish_Ecommerce_Products_by_Gozukara_and_Ozel_2016/All_Products/Raw_Entire_Dataset.txt','r') as file:
for line in file:
if ':' in line :
key, value = line.strip().split(':',1)
structured_data[key.strip()] = value.strip()print(structured_data)
{'38255;LG PW700 BLUETOOTH LED DLP(1280x800), 700 ANSI LUMEN,100.000': '1 KONTRAST,USB,HDMI', '94629;Hp CB324EE No': '364XL Kırmızı Kartuş', '94924;Hp C8721E No': '363 Siyah Mürekkep Kartuş', '96024;PC COMPANY OF HEROES': 'GOTY', '159634;Matlab': 'Yapay Zeka ve Mühendislik Uygulamaları', '160714;ARAL World of Warcraft': 'Warlords of Draenor PC', '191515;Hp CN054A Mavi Kartuş (6100/6600) No': '933XL', '259553;C4906AE Siyah Kartuş No': '940XL', '259766;C8721E Siyah Kartuş No': '363 PS 8250,3210,3310', '262174;CB324EE Yüksek Kapasitesiteli Kırmızı Kartuş No': '364XL D5460,C5380', '301364;ARAL Medal of Honor': 'Warfighter Xbox 360', '325870;CN623AE Kırmızı kartuş No': '971', '342283;NO': '26XL Kartuş Seti XP-600/XP-700/XP-800 C13T26364020', '342289;NO': '26XL Siyah Kartuş XP-600/XP-700/XP-800 C13T26214020', '780829;Corsair 2.5 SSD 240GB CSSD-F240GBGS-BK FORCE GS SATA3 READ': '555MB/S WRITE:525MB/S BRACKET', '966980;Medal of Honor': 'Warfighter'}
Step 3 : Check the type of structured data
type(structured_data)
dict
Step 4 : Convert the structured data (txt) into structured format for statistical modeling and clustering technique
df_structured = pd.DataFrame(list(structured_data.items()), columns=['Product', 'Description'])
print(df_structured.head())
Product \
0 38255;LG PW700 BLUETOOTH LED DLP(1280x800), 70...
1 94629;Hp CB324EE No
2 94924;Hp C8721E No
3 96024;PC COMPANY OF HEROES
4 159634;Matlab
Description
0 1 KONTRAST,USB,HDMI
1 364XL Kırmızı Kartuş
2 363 Siyah Mürekkep Kartuş
3 GOTYtype(df_structured)
pandas.core.frame.DataFrame
Step 5 : Now check the head of the structured data
df_structured.head()
Product Description
0 38255;LG PW700 BLUETOOTH LED DLP(1280x800), 70... 1 KONTRAST,USB,HDMI
1 94629;Hp CB324EE No 364XL Kırmızı Kartuş
2 94924;Hp C8721E No 363 Siyah Mürekkep Kartuş
3 96024;PC COMPANY OF HEROES GOTY
4 159634;Matlab Yapay Zeka ve Mühendislik UygulamalarıStep 6: Form the clustering technique using K Means:
# Since 'Product' and 'Description' are object (string) types, we need to convert them to numerical features before clustering.
# We'll use simple TF-IDF vectorization on the 'Description' column for demonstration.
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(df_structured['Description'])
# Fit KMeans clustering on the vectorized descriptions
kmeans = cluster.KMeans(n_clusters=3, init='k-means++', n_init='auto', random_state=5000)
kmeans.fit(X)
# Assign cluster labels to the dataframe
df_structured['Cluster'] = kmeans.labels_
df_structured.head()
Product Description Cluster
0 38255;LG PW700 BLUETOOTH LED DLP(1280x800), 70... 1 KONTRAST,USB,HDMI 0
1 94629;Hp CB324EE No 364XL Kırmızı Kartuş 1
2 94924;Hp C8721E No 363 Siyah Mürekkep Kartuş 2
3 96024;PC COMPANY OF HEROES GOTY 0
4 159634;Matlab Yapay Zeka ve Mühendislik Uygulamaları 0
print(kmeans.labels_)
[0 1 2 0 0 0 0 0 0 1 0 0 2 2 0 0]
Note :
As you can see our predicted cluster labels are ordered differently, let's do the following to reorder our predicted cluster labels now. The resulting cluster centers from Kmeans are ordered randomly. We compute the distances between these centers and the true group means, then map each KMeans cluster to the closest true cluster using argmin.labels_reorder = df_structured['Cluster'].valuesprint(labels_reorder)
[0 1 2 0 0 0 0 0 0 1 0 0 2 2 0 0]
Step 7 : Check the cluster and predicted cluster has any invalid entry
df_structured['Predicted_cluster'] = pd.Series(labels_reorder, index = df_structured.index)df_structured.head()
Product Description Cluster Predicted_cluster
0 38255;LG PW700 BLUETOOTH LED DLP(1280x800), 70... 1 KONTRAST,USB,HDMI 0 0
1 94629;Hp CB324EE No 364XL Kırmızı Kartuş 1 1
2 94924;Hp C8721E No 363 Siyah Mürekkep Kartuş 2 2
3 96024;PC COMPANY OF HEROES GOTY 0 0
4 159634;Matlab Yapay Zeka ve Mühendislik Uygulamaları 0 0df_structured[df_structured['Cluster'] != df_structured['Predicted_cluster']]Step 8 : Visualization of clusters
cluster_counts = df_structured['Cluster'].value_counts().sort_index()
plt.figure(figsize=(8, 5))
plt.bar(cluster_counts.index, cluster_counts.values, tick_label=[f'Cluster {i}' for i in cluster_counts.index])
plt.xlabel('Cluster')
plt.ylabel('Number of Products')
plt.title('Number of Products per Cluster')
plt.show()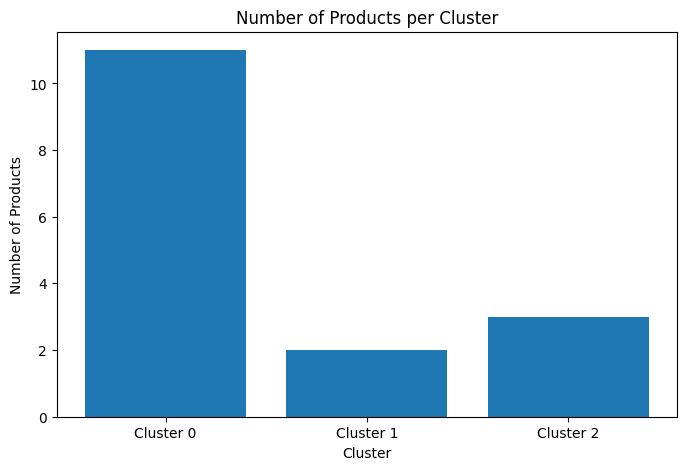
Step 9 : Display the basic statistics of each clusters
# Display basic statistics for each cluster
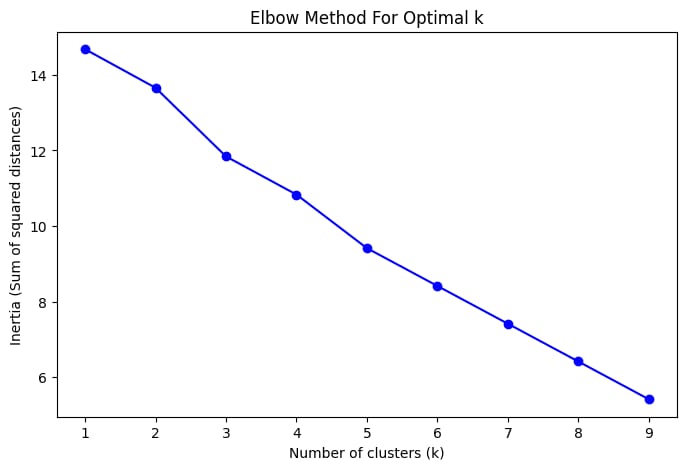
Step 10: Elbow method to determine optimal number of clusters
inertia = []
K = range(1, 10)
for k in K:
km = cluster.KMeans(n_clusters=k, init='k-means++', n_init='auto', random_state=5000)
km.fit(X)
inertia.append(km.inertia_)
plt.figure(figsize=(8, 5))
plt.plot(K, inertia, 'bo-')
plt.xlabel('Number of clusters (k)')
plt.ylabel('Inertia (Sum of squared distances)')
plt.title('Elbow Method For Optimal k')
plt.show()