- Business & Data Research
- Posts
- Logistic Regression - Adclick prediction
Logistic Regression - Adclick prediction
Logistic Regression - Adclick prediction using Python
Mahesh Gurumoorthi
August 13, 2024
Logistic Regression - Adclick Prediction
Logistic regression is a technique used for predictive analysis. It is used for establishing a relationship between one dependent and one or more independent variable. It is also applicable when dependent variable is categorical
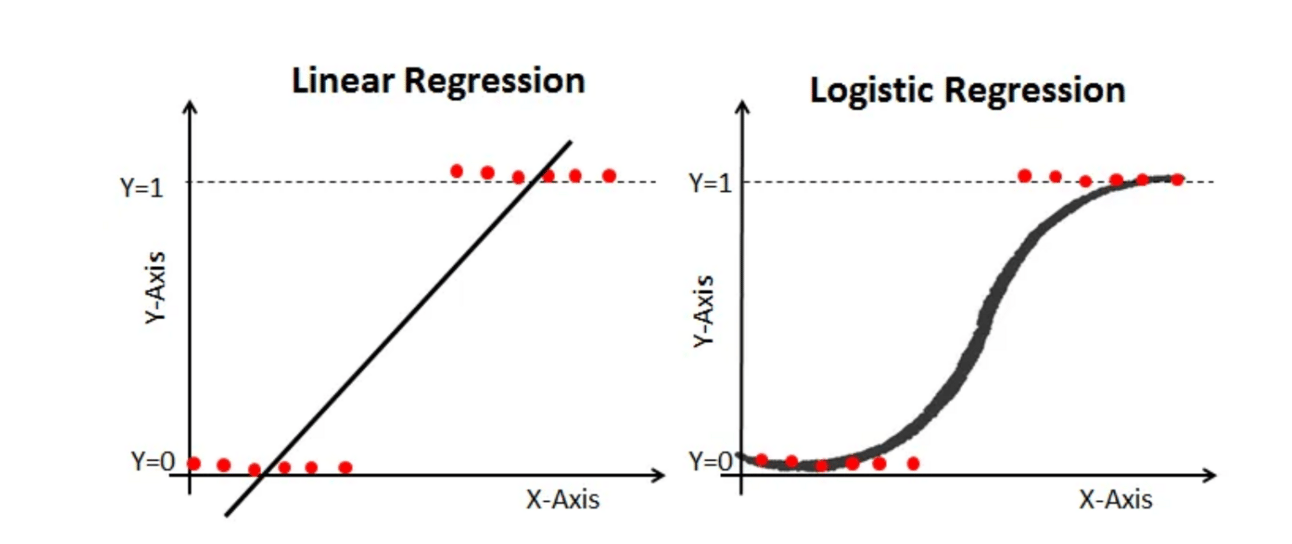
Use Case : We will work with some demographic data to predict whether a user purchased something after clicking on an ad or not. we will start with importing the libraries and datasets
#Basics Required Packages:
import pandas as pd
import numpy as np
#Visualization
import matplotlib.pyplot as plot
import seaborn as sns
import matplotlib.pyplot as plt
#SKLearn ML
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.preprocessing import StandardScaler
Loading the dataset and visualizing the dataset :
#Loading Dataset
social_network_ads = pd.read_csv("/Users/user/Library/CloudStorage/OneDrive-Microsoft365/Social_Network_Ads.csv")
#Displaying the loaded dataframe:
print(social_network_ads)Exploring the dataset:
#Exploring the dataset:
print(social_network_ads.dtypes)
print(social_network_ads.shape)
print(social_network_ads.head())
social_network_ads_bins = social_network_ads[social_network_ads.Age.notna()]
bins = list(range(0,120,10))
social_network_ads_bins['age_range'] = pd.cut(social_network_ads.Age, bins = bins)
chart = sns.catplot(x = "age_range", kind = "count", hue= "Female",
data= social_network_ads_bins);
for axes in chart.axes.flat:
axes.set_xticklabels(axes.get_xticklabels(),rotation = 45)
Using Sklearn library :
We will be using sklearn for fitting the first logistic regression model by splitting the datasets into two chunks : train and test
#Using Sklearn
x_inputs = social_network_ads[['Female','Age','EstimatedSalary']]
y_target = social_network_ads.Purchased
#Splitting into Testing and Training Datasets:
x_train, x_test, y_train, y_test = train_test_split(x_inputs, y_target,train_size=0.8)
Preprocessing step (Scaling data)
Before we fit the logistic regression, we should standardize each input feature, so that all the inputs appear on similar scale and the model is not weighed towards a feature with higher unit values. Standardizing our data transforms it to have a mean of 0 and standard deviation of 1
#Preprocessing Step (Scaling Data) x_train = StandardScaler().fit_transform(x_train) x_test = StandardScaler().fit_transform(x_test)
Fitting the model and evaluation the logistic regression models :
#Define the classifier
classifier = LogisticRegression(max_iter=1000).fit(x_train, y_train)
print(classifier.score(x_train,y_train))
print(classifier.score(x_test,y_test))
#Make predections on test data:
prediction = classifier.predict(x_test)
print(prediction)
#Plot the confusion matrix
(plot_confusion_matrix(classifier,x_train,y_train))