- Business & Data Research
- Posts
- Natural Language Processing - Vader and Roberta Pre-Trained Model using Financial Dataset
Natural Language Processing - Vader and Roberta Pre-Trained Model using Financial Dataset
NLTK, NLP
Mahesh Gurumoorthi
September 09, 2025

What is Natural Language Processing (NLP) ?
Natural Language Processing (NLP) is a branch of artificial intelligence that helps computers understand, interpret, and generate human language—just like we do when we speak, write, or read.
How does it work?
Together, these allow machines to:
Break down sentences into parts (syntax)
Understand meaning and context (semantics)
Respond or generate text that feels natural
About the dataset: I took the financial dataset from the market and performed the index rate , and reviewed the comments using NLP
Step 1: Import the required libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('ggplot')
import nltkStep 2: Read the dataset
financial_data = pd.read_csv('/Users/FinancialNews/financial_news_events.csv')financial_data.head()
Remove the NaN values using dropna() and ensure all the values are properly removed
financial_new_df = financial_data.dropna()financial_new_df.isna().sum()
Date 0
Headline 0
Source 0
Market_Event 0
Market_Index 0
Index_Change_Percent 0
Trading_Volume 0
Sentiment 0
Sector 0
Impact_Level 0
Related_Company 0
News_Url 0
dtype: int64financial_new_df.head()
financial_new_df.shape
(2443, 12)financial_new_df.ndim
2
Step 3: Perform the quick EDA
financial_new_df['Index_Change_Percent'].value_counts().sort_index().plot(kind = 'bar',title = ' Count of Trading Volume by Population',
figsize= (10,5))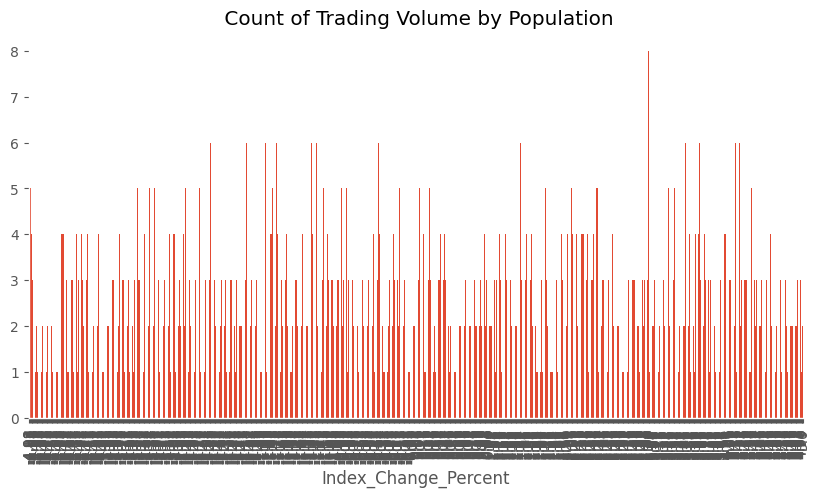
Step 4 : Basic NLTK using example object and taken sample sentences from the main dataset
from nltk.tokenize import word_tokenizeexample = financial_new_df['Headline'][500]
print(example)tokens = nltk.word_tokenize(example)print(tokens)
['Consumer', 'confidence', 'index', 'reaches', 'a', 'decade', 'high']
tokens[:3]
['Consumer', 'confidence', 'index']
tagged = nltk.pos_tag(tokens)tagged[:10]
[('Consumer', 'NNP'),
('confidence', 'NN'),
('index', 'NN'),
('reaches', 'VBZ'),
('a', 'DT'),
('decade', 'NN'),
('high', 'JJ')]entities = nltk.chunk.ne_chunk(tagged)entities.pprint()
(S
(GSP Consumer/NNP)
confidence/NN
index/NN
reaches/VBZ
a/DT
decade/NN
high/JJ)Step 5: Sentimental Analysis: VADER sentiment scoring method
from nltk.sentiment import SentimentIntensityAnalyzerfrom tqdm.notebook import tqdmsia = SentimentIntensityAnalyzerNote: Polarity Scores define negative, neutral and positive measures. Compound score between -1 to +1
sia().polarity_scores(example)
{'neg': 0.0, 'neu': 0.471, 'pos': 0.529, 'compound': 0.5423}
financial_new_df.head()
Step 6: Run the polarity score on the entire dataset
### Run the polarity score on the entire dataset
res = {}
for i, row in tqdm(financial_new_df.iterrows(), total = len(financial_new_df)):
text = row['Headline']
myid = row['Index_Change_Percent']
res[myid] = sia().polarity_scores(text)
breakres = {}
for i, row in tqdm(financial_new_df.iterrows(), total=len(financial_new_df)):
text = row['Headline']
myid = row['Index_Change_Percent']
res[myid] = sia().polarity_scores(text)res
{-0.05: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
-2.29: {'neg': 0.0, 'neu': 0.659, 'pos': 0.341, 'compound': 0.4767},
-3.97: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
0.56: {'neg': 0.0, 'neu': 0.745, 'pos': 0.255, 'compound': 0.34},
-3.68: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
-4.33: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
3.35: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
-1.66: {'neg': 0.0, 'neu': 0.769, 'pos': 0.231, 'compound': 0.4588},
-2.45: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
0.92: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
2.83: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
-2.92: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
4.41: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
4.15: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
-0.95: {'neg': 0.0, 'neu': 0.732, 'pos': 0.268, 'compound': 0.296},
-2.37: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
-1.96: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
4.28: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
-2.02: {'neg': 0.0, 'neu': 0.714, 'pos': 0.286, 'compound': 0.4215},
1.34: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
-1.18: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
2.46: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
-4.4: {'neg': 0.0, 'neu': 0.745, 'pos': 0.255, 'compound': 0.34},
3.53: {'neg': 0.0, 'neu': 0.741, 'pos': 0.259, 'compound': 0.2732},
-3.44: {'neg': 0.0, 'neu': 0.714, 'pos': 0.286, 'compound': 0.4215},
...
-4.92: {'neg': 0.0, 'neu': 0.66, 'pos': 0.34, 'compound': 0.5574},
-1.97: {'neg': 0.0, 'neu': 0.745, 'pos': 0.255, 'compound': 0.34},
4.25: {'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0},
1.79: {'neg': 0.216, 'neu': 0.784, 'pos': 0.0, 'compound': -0.296},
-4.5: {'neg': 0.0, 'neu': 0.769, 'pos': 0.231, 'compound': 0.4588}}Step 8: Make the res object into a Dataframe, so that it would be easy to merge with mthe ain dataset
vaders = pd.DataFrame(res).T
vaders.reset_index().rename(columns= {'index':'Id'})
financial_new_df = financial_new_df.reset_index().rename(columns={'index': 'Id'})Step 9: Now we have a sentimental score of metadata
vaders = vaders.merge(financial_new_df, how='left', left_index=True, right_on='Index_Change_Percent')vaders.head()
Step 10: Create Barplot and this plot gives the compound score. Compound score gives the entire persption of the sentence, if it is +1 which means positive and -1 means negative (customer not satisfied)
ax = sns.barplot(data = vaders, x = 'Index_Change_Percent', y = 'compound')
ax.set_title('Compound score by Financial dataset')
plt.show()
fig, axs = plt.subplots(1,3, figsize = (12,3))
sns.barplot(data=vaders,x = 'Index_Change_Percent', y = 'pos',ax = axs[0])
sns.barplot(data=vaders, x = 'Index_Change_Percent', y = 'neu', ax = axs[1])
sns.barplot(data=vaders, x = 'Index_Change_Percent', y = 'neg',ax = axs[2])
axs[0].set_title('Positive')
axs[0].set_title('Neutral')
axs[0].set_title('Negative')
plt.tight_layout()
plt.show()
Step 11: Perform Vader Model
Before entering into this model, let’s explain more about this in simple terms.
Sentimental Analysis: VADER Sentiment Scoring [VADER - Valence Aware Dictionary and Sentiment Reasoner]
Importing the required libraries for vader model 😀
from nltk.sentiment import SentimentIntensityAnalyzerfrom tqdm.notebook import tqdmsia = SentimentIntensityAnalyzertext = 'I am so happy !'Note: Polarity Scores define negative, neutral and positive measures. Compound score between -1 and +1
sia().polarity_scores(text)
{'neg': 0.0, 'neu': 0.318, 'pos': 0.682, 'compound': 0.6468}sia().polarity_scores(example)
{'neg': 0.0, 'neu': 0.471, 'pos': 0.529, 'compound': 0.5423}Step 12: Create a function to iterate over the financial dataframe and store the sentiment intensity analyzer of this dataframe in an object
res = {}
for i, row in tqdm(financial_new_df.iterrows(), total=len(financial_new_df)):
text = row['Headline']
myid = row['Index_Change_Percent']
res[myid] = sia().polarity_scores(text)### Vader results
print(example)
Consumer confidence index reaches a decade highsia().polarity_scores(text)
{'neg': 0.0, 'neu': 0.769, 'pos': 0.231, 'compound': 0.4588}Step 13: Now perform the Roberta Pre-Trained Model
MODEL = f"cardiffnlp/twitter-roberta-base-sentiment"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
model = TFAutoModelForSequenceClassification.from_pretrained(MODEL)# Run for Roberta Model
encoded_text = tokenizer(example, return_tensors='tf')
output = model(**encoded_text)
scores = output[0][0].numpy()
scores = softmax(scores)
scores_dict = {
'roberta_neg' : scores[0],
'roberta_neu' : scores[1],
'roberta_pos' : scores[2]
}
print(scores_dict)
{'roberta_neg': np.float32(0.011778387), 'roberta_neu': np.float32(0.47179228), 'roberta_pos': np.float32(0.5164293)}### Run for Roberta Model using functions :
def polarity_scores_roberta(example):
encoded_text = tokenizer(example, return_tensors='tf')
output = model(**encoded_text)
scores = output[0][0].numpy()
scores = softmax(scores)
scores_dict = {
'roberta_neg' : scores[0],
'roberta_neu' : scores[1],
'roberta_pos' : scores[2]
}
return scores_dictresults_df = pd.DataFrame(res).T
results_df = results_df.reset_index().rename(columns={'index': 'Index_Change_Percent'})
results_df = financial_new_df.merge(results_df, how='left')
display(results_df.head())
Step 14: Analyze the sentiment of the Headline column in the DataFrame financial_new_df using VADER and RoBERTa models, compare the results with the existing Sentiment column, and visualize the sentiment distributions.
Apply Vader and Roberta sentiment analysis
Subtask:
Apply VADER and RoBERTa sentiment analysis to the Headline column of the financial_new_df DataFrame and store the results in new columns.
res = {}
sia_instance = sia()
for i, row in tqdm(financial_new_df.iterrows(), total=len(financial_new_df)):
try:
text = row['Headline']
vader_result = sia_instance.polarity_scores(text)
roberta_result = polarity_scores_roberta(text)
res[i] = {
'vader_neg': vader_result['neg'],
'vader_neu': vader_result['neu'],
'vader_pos': vader_result['pos'],
'vader_compound': vader_result['compound'],
'roberta_neg': roberta_result['roberta_neg'],
'roberta_neu': roberta_result['roberta_neu'],
'roberta_pos': roberta_result['roberta_pos']
}
except RuntimeError:
print(f'Broke for index {i}')results_df = pd.DataFrame(res).T
results_df = results_df.dropna()
results_df = results_df.reset_index().rename(columns={'index': 'Index_Change_Percent'})
results_df = financial_new_df.merge(results_df, how='left')
display(results_df.head())
Step 15: Combine and compare the Vader model and Roberta model
